
Die Reihenfolge der Zeilen und Siglen in der Zeilensynopse sowie die Reihenfolge und Datierung der Balken im Balkendiagramm beruhen auf einem experimentellen Teil der Edition, dem Makrogenese-Lab. Vgl. hierzu auch Vitt et al. 2019.
Modellierung ¶
Hierfür wurden die für relevant erachteten Quellen aus der Forschungs- und Editionsgeschichte zu Faust ausgewertet. Als Kriterium für die Auswahl diente nicht die Plausibilität der jeweiligen Annahmen, sondern der konkrete Bezug auf die Überlieferung.Aufgenommen wurden auch Annahmen, die lediglich forschungsgeschichtlich relevant sind. Allgemeine Annahmen über die mutmaßliche Entstehungszeit von Teilen des Werks wurden dagegen nicht berücksichtigt. Die Erkenntnisse, die im Rahmen der Arbeit an der Faustedition gewonnen und noch nicht separat publiziert sind, wurden als Selbstaussagen (self) aufgenommen. Die Forschungsaussagen wurden nach einem einfachen Modell in XML codiert: Einzelne Zeugen können untereinander in einer zeitlichen Reihenfolge stehen sowie mit einem möglichen Entstehungszeitraum assoziiert werden. Ungefähre oder vage Angaben (z.B. „1800/1801“ oder „Frühsommer“) wurden dabei zu eindeutig definierten Zeitintervallen normiert und nach Möglichkeit interpretatorisch präzisiert.
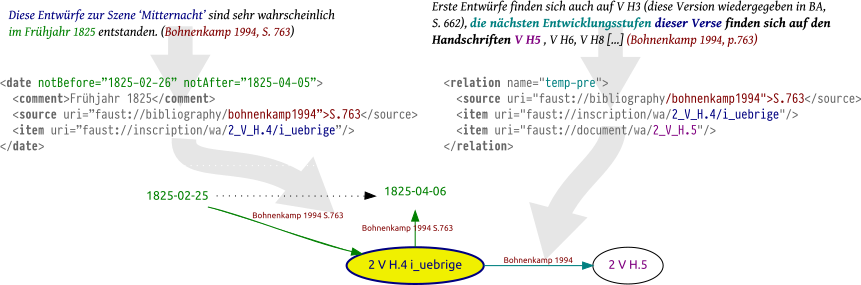
Diese Aussagen wurden dann zu einem großen Gesamtgraphen miteinander verknüpft.
Ein Graph setzt sich zusammen aus Objekten (graphentheoretisch: Knoten), zwischen denen Relationen (Kanten) bestehen. Die Knoten werden in diesem Fall durch Zeugen und tagesgenaue Datumsangaben gebildet, die Kanten durch zeitliche Verhältnisse (z.B. Handschrift a entstand vor Handschrift b, das Datum 25. Februar 1825 liegt vor der Entstehung von Handschrift c). Der Graph ist gerichtet, d.h. die Richtung der Kanten ist relevant: Eine Kante x → y drückt immer das Verhältnis „x vor y“ aus.
Analyse ¶
Sobald die Einzelaussagen zu einem Gesamtzusammenhang verknüpft werden, treten Widersprüche zwischen Forschungsaussagen als Zyklen zutage. Insbesondere bildet sich ein großes Widerspruchscluster (in der Sprache der Graphentheorie eine stark zusammenhängende Komponente) mit über 2000 Aussagen zu fast 500 Zeugen, in der die (vermutlich) falschen Aussagen nicht mehr mit bloßem Auge zu identifizieren sind. Deshalb wurde automatisch eine Menge von Aussagen identifiziert, die bei der Bildung des Gesamtgraphen ausscheiden sollen – im Makrogenese-Lab Konfliktkanten genannt und rotgestrichelt dargestellt. Die Auswahl der Konfliktkanten geschieht nach mehreren Kriterien:
- Grundsätzlich wird angestrebt, möglichst viele Aussagen in den Graphen zu integrieren (d.h. die Anzahl der ausgeschiedenen gering zu halten).
- Einzelne Kanten können ein größeres Gewicht erhalten durch
- die Glaubwürdigkeit der Quelle aus heutiger Sicht (formuliert durch ein einfaches Punktesystem),
- durch Addition gleichlautender Aussagen.
Einige Aussagen werden bereits vor der heuristischen Konfliktbeseitigung aus dem Graphen entfernt: weil die Quelle entweder insgesamt als lediglich forschungsgeschichtlich relevant gilt (Hertz 1931) oder weil eine einzelne Aussage als offensichtlich unbegründet markiert wurde. Aussagen über Gleichzeitigkeit zwischen Zeugen werden bei der Konstruktion des Graphen ebenfalls nicht berücksichtigt, weil sie keine gerichtete Beziehung ausdrücken. Alle diese nicht berücksichtigten Kanten erscheinen in den Visualisierungen grau.
Auswertung ¶
Der verbleibende Graph ist zyklen- und damit widerspruchsfrei. Damit besteht die Möglichkeit, seine Knoten in eine Reihenfolge zu bringen, die keiner der verbliebenen Aussagen widerspricht (eine topologische Sortierung). Diese Reihenfolge ist nicht eindeutig, zur Auflösung von Ambiguitäten wurden als sekundäre Kriterien das Syntagma (konkret: der erste vorkommende Faustvers) und die Siglierung herangezogen. Die auf diese Weise disambiguierte Reihenfolge dient als Grundlage der Sortierung der Zeilen und Siglen in der Zeilensynopse sowie der Balken im Balkendiagramm.
Dieser Graph dient darüber hinaus auch einer Abschätzung des Entstehungszeitraums eines Zeugen, wie sie im Balkendiagramm ganz links visualisiert wird. Dazu wird jeweils das nächste vom Zeugen erreichbare Datum in Vorwärts- oder Rückwärtsrichtung herangezogen.
Das Makrogenese-Lab versteht sich als Werkzeug nicht nur zum Nachvollziehen der in der Faustedition sichtbaren Einordnung, sondern insbesondere auch zur weiteren Forschung und Verbesserung der Daten. Es gibt deshalb nicht nur zu jedem Zeugen (Beispiel) eine interaktive Visualisierung auf der Basis der Software Graphviz mit Einordnung und eine Darstellung der unmittelbar assoziierten Aussagen, sondern auch etwa eine Darstellung aller entfernten Konfliktkanten mit individueller Visualisierung des Widerspruchs, sowie Darstellungen pro Szene oder pro Quelle. Eine Legende erläutert die Visualisierungen im Detail.
Grenzen und Herausforderungen ¶
All models are wrong, but some are useful.
Die Makrogenese-Modellierung aggregiert Abstraktionen von Datierungsaussagen aus der Literatur. Sie liefert dementsprechend nicht die Reihenfolge der Zeugen, sondern vielmehr eine mögliche Reihenfolge, die mit möglichst vielen der Aussagen kompatibel ist – oder zumindest mit der oben beschriebenen Modellierung der Aussagen.
Aus Modellierung und Datenbestand ergeben sich eine Reihe von Einschränkungen, die zu Abweichungen von der Realität führen können:
-
Für die Datierungsaussagen mit unscharfen oder unsicheren Datierungen wird dennoch im Modell eine „scharfe“ Vorher-Nachher-Beziehung bzw. ein konkretes Zeitintervall angesetzt. Dies ist natürlich nur eine Näherung; eine unschärfere Modellierung und die Berücksichtigung weiterer Beziehungen zwischen den Intervallen ist Gegenstand der Forschung.
-
Inskriptionen sind nur unzureichend modelliert.
Bei der Datierung werden eigentlich Inskriptionen untersucht, also zusammenhängende Schreibakte bzw. deren materielle Hinterlassenschaft. Die Zeugen-Einheit, mit der in der Edition gearbeitet wird, sind jedoch Archivalien. Das Makrogenese-Modell sieht zwar Äußerungen sowohl über Zeugen (Archivalien) als auch über Inskriptionen vor und modelliert auch deren Zusammenhang, jedoch: Zum einen sind Inskriptionen und ihr Ausmaß nicht immer leicht zu erkennen (und dementsprechend auch nur eingeschränkt in den Transkriptionen ausgezeichnet), zum anderen ist auch in den Datierungsaussagen in der Literatur nicht immer klar, auf welchen Teil eines Zeugen sie sich beziehen, und schließlich ist die Semantik unklar, wenn sowohl eine Aussage über ein Archivale als auch über eine Inskription darauf vorliegt: Beginnt die Arbeit am Archivale vor der ersten und endet nach der letzten Inskription? Bezieht sich die Aussage über das Archivale möglicherweise nur auf eine Inskription auf dem Blatt?
-
Die Auswahl der Konfliktkanten erfolgt nach formalen statt nach philologischen Kriterien, gerade weil der Gegenstand zu komplex für eine umfassende rein philologische Betrachtung ist. Die Vorauswahl kann natürlich durch eine entsprechende Anpassung des Modells beeinflusst werden, wenn fehlerhafte Entscheidungen des Verfahrens identifiziert werden. Fehlerberichte sind willkommen.
-
Für viele Handschriften liegt keine absolute Datierung vor, oder nur eine Hälfte (also nur frühester oder spätester Entstehungszeitpunkt, nicht beide). Über Zeugen, deren relativer Bezug bekannt ist, kann oft die Datierung transitiv weiter eingegrenzt werden, dabei wird aber die Richtigkeit aller Aussagen auf dem entsprechenden Pfad angenommen, und es wird zur Datierung arbiträr das „engste“ Intervall, also der späteste terminus post quem und der früheste terminus ante quem herangezogen.
Darüberhinaus wird zur Datierung bei Vorliegen nur einer Intervallgrenze die andere (mit sehr niedriger Priorität) im Abstand von sechs Monaten angenommen, in der Annahme, dass die „einseitige“ Datierung eine zeitliche Nähe zum Datum impliziert. Die niedrige Priorität bewirkt, dass diese Kanten im Fall eines Konflikts bevorzugt ausgeschieden werden.